After upgrading NetScaler to build 14.1 47.46 or 13.1 59.19 customers might experience issues with Authentication.This can manifest as a «broken» login page, especially when using authentication methods like DUO configurations based on Radius authentication, SAML, or any Identity Provider (IDP) that relies on custom scripts.
Note : This behavior can possibly be due to the Content Security Policy (CSP) header being enabled by default in this NetScaler build, especially when CSP was not enabled prior to the upgrade.
Lösung
To resolve this issue temporarily, you need to disable the default CSP header on your NetScaler appliance. After disabling, it’s recommended to flush the cache to ensure the changes take effect immediately.
To ensure that your configurations work with CSP , please reach out to the support team so that we can identify the issue and fix it for your configuration.
Steps to Disable CSP Header:
Using Command Line Interface (CLI): Execute the following commands from Netscaler CLI:
set aaa parameter -defaultCSPHeader DISABLED
save ns config
Using Graphical User Interface (GUI):
Step 1: Log in to the NetScaler GUI.
Step 2: Navigate to NetScaler Gateway > Global Settings.
Step 3: Under the «Authentication Settings» section, click on Change authentication AAA settings.
Step 4: On the «Configure AAA Parameters» page, locate the Default CSP Header field. From the dropdown menu, select DISABLED.
Click OK to save the changes.
Post-Configuration Recommendation:
While enabling or disabling the default CSP policy, you are recommended to run the following command in the CLI
flush cache contentgroup loginstaticobjects
After performing the steps above, attempt to access your NetScaler Gateway authentication portal to validate if the issue is resolved.
Zusatz
Bei Fragen und Problemen können Sie sich gerne an Ihren AXACOM Verantwortlichen wenden.
Kunden, die auf ihrem NetScaler Kerberos verwenden, bekommen nach dem Microsoft November Update ein Problem. Kerberos funktioniert danach nicht mehr mit dem NetScaler und auch weitere Umsysteme sind davon betroffen. Sie erhalten bei einem Login Versuch via NetScaler folgenden Eintrag im System Eventlog des Domain Controllers:
While processing an AS request for target service <service>, the account <account name> did not have a suitable key for generating a Kerberos ticket (the missing key has an ID of 1). The requested etypes : 18 3. The accounts available etypes : 23 18 17. Changing or resetting the password of <account name> will generate a proper key.
ACHTUNG: Diese Anpassungen sind nur als Workaround zu verstehen und sollten wieder rückgängig gemacht werden, sobald Microsoft einen Fix für den Fehler bereitstellt!
UPDATE 18.11.2022
Microsoft hat ein OOB Update für Domain Controller veröffentlicht, welches das oben beschriebene Problem löst.
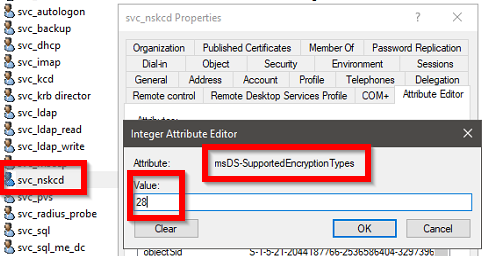
Nach der Installation des Updates auf allen Domain Controllern ist es möglich RC4 wieder vom KCD Account zu entfernen (Attribut: msDS-SupportedEncryptionTypes, Value: 24) und falls gesetzt, den Reg Key «KrbtgtFullPacSignature» wieder zu entfernen.
Seit dem 01.01.2022 – 00:00 Uhr werden aufgrund eines Bugs bei On-Prem Exchange Servern keine Mails mehr zugestellt. Neue Mails werden vom Exchange zwar angenommen, bleiben dann aber in der Submission Queue hängen und werden nicht ausgeliefert.
Ursache ist ein Bug im “Microsoft Filtering Management Service”, der sich am Jahr 2022 verschluckt. Im Application Event log finden sich dann viele Fehlermeldungen des FIPFS Services mit Meldungen wie «Cannot convert “220101001” to long»
Als Quick Fix reicht es, den «AntiMalware Scanning Service» temporär via Disable-Antimalwarescanning.ps1zu disablen.
In dem Beitrag findet sich etwas versteckt ein Download Link für ein PowerShell Script, welches diesen Prozess automatisiert: https://aka.ms/ResetScanEngineVersion
Das Script läuft recht lange (bis zu 30 Min.) Anschliessend musste der «Microsoft Exchange Transport» Service neu gestartet werden, um den Mailfluss wieder in Gang zu bringen.
HPE warnt erneut vor dem Ausfall von Enterprise SSD’s.
Ein Fehler in der Firmware kann bei betroffenen SSD’s zu Datenverlust führen, sobald diese 40’000 Betriebsstunden erreichen.
Betroffen sind HPE SSD’s mit den Modellnummern:
EK0800JVYPN
EO1600JVYPP
MK0800JVYPQ
MO1600JVYPR
Der Hersteller verbaut diese in den Systemen ProLiant, Synergy, Apollo 4200, Synergy Storage Modules, D3000 Storage Enclosure und StoreEasy 1000 Storage. Die Firmware-Version HPD7 vom 20. März 2020 behebt das Problem.
Den eigenen Daten zufolge sollen ohne Firmware-Update im Oktober 2020 die ersten SSDs bei Kunden ausfallen.
Die Webseite Blocks & Files hat ein gleich klingendes Firmware-Problem bei Dell entdeckt, dessen Support vor Ausfällen nach 40.000 Betriebsstunden warnte. Schuld ist demnach ein falsch gesetzter Check mit N-1 statt N. Laut Dell kommen bei den betroffenen Modellen neun verschiedene SSDs der Western-Digital-Tochter SanDisk mit Kapazitäten von 200 GByte bis 1,6 TByte zum Einsatz. Die Zulieferernummern auf den HPE-Datenträgern sprechen ebenfalls für SSDs von SanDisk. Auch Dell stellt entsprechende Firmware-Updates bereit.